访谈|#NLP太难了# 未来媒体访谈对话黄萱菁教授|“NLP+媒体”:科技向善,做有挑战的事( 七 )
未来媒体访谈:测了舆情之后,还是要去看人群的用户画像,或者说它的精细化的情感分析,对情感分析这一方面,一个非常常识的猜测是它肯定是偏负向的,除了偏负向的发现之外,还有什么发现?
黄萱菁:我们只关注了一个月的时间,但实际上情绪变化已经很多了,初期有严重负面的情绪,后面就逐渐向好,虽然有小的振荡。总的说来,疫情的初期,负向的微博文本特别多,因为对于突出其来的这样的公共卫生事件,网络中间就弥散了很多的恐慌和不安,随着钟南山、张文宏这些专家学者介入,然后政府出台各种各样有效的防控措施,正向的情感就不断提高了。
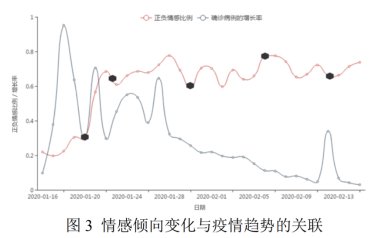
文章插图
另外我们还做了一些疫情中间的群体画像,比如看哪个职业的声音大对吧?如果发现早期是自由职业者、明星、自媒体比较活跃,后面的话企业界管理人员、专业技术人员就开始活跃起来。
我们还看的是哪里的声音,对吧?全国各地的用户对舆情的关注度怎么样?
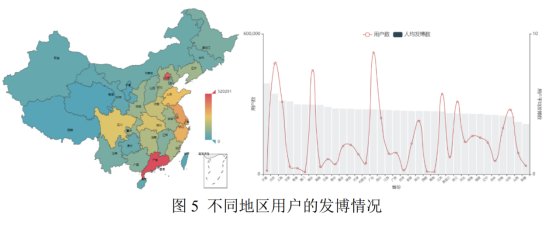
文章插图
那么就会发现,尽管广东和北京的是声音是特别大的,他们不仅是参与的用户多,发声也非常积极,东南沿海相对次之,然后甚至像西北,宁夏、甘肃还有像海南,用户不多,但是活跃度也很高,反而当时疫情的焦点——湖北的用户发言的积极度是处于中等水平。还有话题讨论,一开始新一线城市参与的讨论就很积极,后面话题就不断下沉到三、四、五线这样的城市群体。
“怎么样判断我们的微博会不会热门?”
未来媒体访谈:像我们刚才聊的,比如微博热搜,这一块就是回到社会媒体信息处理应用场景,这里其实有非常多的任务都是典型的NLP任务,不管是热榜,还是微博问答,或者反垃圾机制,都要牵扯到一个贴标签的问题,针对于社交媒体的文本,我们怎么样去做更精准的标签推荐?
黄萱菁:标签推荐我们实验室做了好多年了,我们早期的话是用机器学习的方法,后面我们用的是深度学习方法。大概是这样,首先我们要处理一个任务的话,我们要对它进行建模,怎么样去用一个数学模型去处理它,就有两个思路,一个思路是生成,就是说标签是不一定的,可以按照自然语言生成的技术,你给我一篇文章,就给它产生一个标签。为什么这几年深度学习在自然语言处理这个方面特别轰动?
刚才我也提到过,以前的自然语言理解,我们做的更多的是理解,相当于我们考语文考英语,我们做的是阅读理解,但是写作文、组词造句做得不是很好,有了神经网络之后,我们写作文的能力就有很大提升了。
那么写作文,广义叫写作对吧?当然有很多形式的写作,可以写长篇大论,可以写小说,对吧?也可以写标签、提取关键词,这也是我们可以采用生成的工具去做的,可以采用深度学习常见的我们叫编码器—解码器的框架去做,这是一个思路。
还有一个思路是把它当成分类,因为标签一定是很长尾的,对吧?有时候你有标签的话,你希望这个标签跟大家形成一个话题,好跟有相同话题的人去交流,如果你这个标签打的太小众,生成的可能跟别人标签不太一样,就很难形成话题了,所以我们可以在现成的标签中间去挑一个相关的,这样就相当于是一个分类。那么这两个思路都可以,需要看我们是想要生成标签是更加多样化,还是希望我们生成标签是更加主流、更加有可能是现有热点,所以我们这两类方法我们都做过。
未来媒体访谈:如果说对于普通用户,他想注册一个微博的小号,然后他去进行维权或者发布一些求助方面的信息,也就是说他没有历史信息,但是如果他想去进行维权的话,他会发很长段的一些叙述的文字,然后@一些大v或者是官博官媒,这一块的 @推荐应该怎么做?
推荐阅读











- 中关村|焦点访谈丨“双减”一学期,效果如何
- 中关村|焦点访谈丨“双减”一学期 效果如何
- 时间|焦点访谈丨“双减”一学期 效果如何
- 中关村|焦点访谈:“双减”一学期 效果如何
- 时间|焦点访谈:“双减”一学期 效果如何
- 阅读理解|期末考试阅读题太难,学生喊话作家求“标准答案”,折射了啥?
- 排球|焦点访谈:体教融合 新思路新探索
- 青少年|焦点访谈:体教融合 新思路新探索
- 微博|学生喊话期末阅读题太难,著名作家回应
- 教师|双减之后,高三普通班复习课太难上,教师:过度关注成绩,很肤浅