
文章插图
·GPT-4可以接受图像和文本输入,而GPT-3.5只接受文本;GPT-4在各种专业和学术基准上的表现达到“人类水平”,在事实性、可引导性和可控制方面取得了“史上最佳结果”;当任务的复杂性达到足够的阈值时,GPT-4比GPT-3.5更可靠,更有创造力,能够处理更细微的指令 。
·OpenAI承认,GPT-4并不完美,仍然会对事实验证的问题产生错乱感,也会犯一些推理错误,偶尔过度自信 。OpenAI将开源OpenAI Evals,用于创建和运行评估GPT-4等模型的基准 。
3月14日,ChatGPT的开发机构OpenAI正式发布其里程碑之作GPT-4 。
GPT-4是一个多模态大模型(接受图像和文本输入,生成文本) 。相比上一代的GPT-3,GPT-4可以更准确地解决难题,具有更广泛的常识和解决问题的能力:更具创造性和协作性;能够处理超过25000个单词的文本,允许长文内容创建、扩展对话以及文档搜索和分析等用例 。
此外,GPT-4的高级推理能力超越了ChatGPT 。在SAT等绝大多数专业测试以及相关学术基准评测中,GPT-4的分数高于ChatGPT 。
OpenAI花了6个月时间使GPT-4更安全、更具一致性 。在内部评估中,与GPT-3.5相比,GPT-4对不允许内容做出回应的可能性降低82%,给出事实性回应的可能性高40%。GPT-4引入了更多人类反馈数据进行训练,不断吸取现实世界使用的经验教训进行改进 。
不过,OpenAI表示,GPT-4仍然有许多正在解决的局限性,例如社会偏见、幻觉和对抗性prompt(提示) 。
目前,OpenAI在付费版的ChatGPT Plus上提供GPT-4,并为开发人员提供API以构建应用和服务 。值得一提的是,微软的新必应(New Bing)早就用上了GPT-4 。
OpenAI还开源了Evals框架,以自动评估AI模型性能,允许用户报告模型中的缺点,帮助其改进 。
“GPT-4是世界第一款高体验,强能力的先进AI系统,我们希望很快把它推向所有人 。”OpenAI工程师在介绍视频里说 。

文章插图
OpenAI在官网发布公告,宣布推出GPT-4
比GPT-3.5更可靠,更有创造力
GPT是Generative Pre-training Transformer(生成式预训练Transformer)的缩写 。OpenAI于2018年推出具有1.17亿个参数的GPT-1模型,2019年推出具有15亿个参数的GPT-2,2020年推出有1750亿个参数的GPT-3 。ChatGPT是OpenAI对GPT-3模型微调后开发出来的对话机器人 。
3月14日,OpenAI在其官网上发布了推出GPT-4的公告 。公告称,OpenAI已正式推出GPT-4,这也是OpenAI在扩大深度学习方面的最新里程碑 。GPT-4是大型多模态模型,尽管在许多现实世界的场景中能力不如人类,但它可以在各种专业和学术基准上,表现出近似人类水平的性能 。
例如:GPT-4通过了模拟的律师考试,分数约为全部应试者的前10% 。而相比之下,GPT-3.5的分数大约是后10% 。“我们团队花了6个月时间,利用对抗性测试项目以及基于ChatGPT的相关经验,反复对GPT-4进行调整 。结果是,GPT-4在事实性(factuality)、可引导性(steerability)和拒绝超范围解答(非合规)问题方面取得了有史以来最好的结果(尽管它还不够完美) 。”
OpenAI表示,在过去两年里,他们重构了整个深度学习堆栈,并与Azure(微软云服务)合作,共同设计了一台超级计算机 。一年前,OpenAI训练了GPT-3.5,作为整个系统的首次“试运行” 。他们发现并修复了一些错误,改进了之前的理论基础 。“因此,我们的GPT-4训练、运行(自信地说:至少对我们来说是这样!)空前稳定,成为我们首个训练性能可以进行提前准确预测的大模型 。随着我们继续专注于可靠扩展,中级目标是磨出方法,以帮助OpenAI能够持续提前预测未来,并且为未来做好准备,我们认为这一点对安全至关重要 。”
OpenAI承认,在简单闲聊时,也许不太好发现GPT-3.5和GPT-4之间的区别 。但是,当任务的复杂性达到足够的阈值时,它们的区别就出来了 。具体来说,GPT-4比GPT-3.5更可靠,更有创造力,能够处理更细微的指令 。
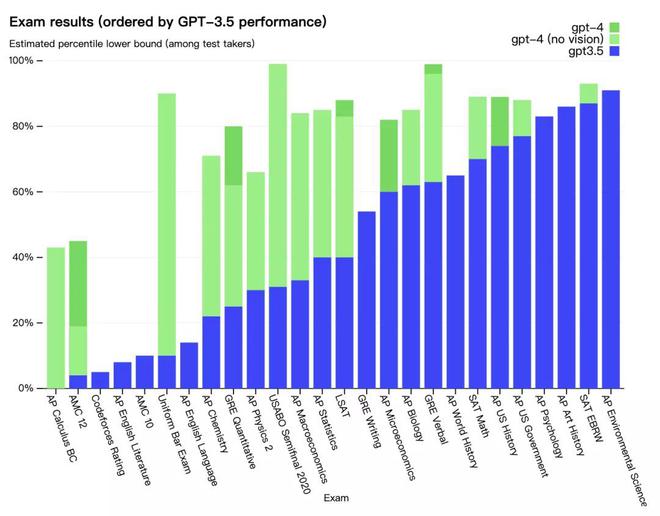
文章插图
GPT-4相比GPT-3.5在各项考试中的成绩
为了理解这两个模型之间的差异,OpenAI在各种不同的基准上进行了测试,包括模拟为人类设计的考试 。“我们还在为机器学习模型设计的传统基准上对GPT-4进行了评估 。GPT-4大大超过现有的大语言模型,与多数最先进的(SOTA)模型并驾齐驱 。”
推荐阅读










- iPhone 13 Mini规格参数 苹果13mini屏幕多大尺寸
- 华为手机定时开关机设置方法 华为如何关机手机
- 桑塔纳55000公里保养 桑塔纳一般保养多少钱
- 怎么才能当警察 如何才能当警察
- 夏天开空调几度最省电又凉快 格力26度空调开一晚多少钱
- 乾坤运转喜事多代表什么生肖 乾坤是什么生肖
- iPhone11ProMax的电池容量是多少(苹果11电池续航数据讲解
- 拼多多怎么开网店 拼多多如何开网店
- 空调清洗上门服务多少钱 空调网清洗怎么拆开
- 转账频繁怎么和银行解释 转账频繁被冻结多久解除